...
For the purposes of this document, user provisioning is defined to be the processes, both human and automated, that authorize (and de-authorize) people to use application systems, when those processes occur at times other than the start of an online session. This is distinguished from application systems that use a "pure" single sign-on infrastructure (e.g., Shibboleth), authorizing anyone with a defined set of attributes that are provided at the start of a session.
The infrastructure described in this document will support the exchange of identity information from campus Identity and Access Management (IAM) systems to application systems, not the entire set of provisioning processes. The Roles and Responsibilities section below describes where those other provisioning processes should be implemented.
...
- Snapshot. All identity information allowed by the attribute release policy will be transmitted to the application.
- Subscription. Identity information will be transmitted to the application as add, delete, and update transactions on an event-driven basis. The transactions sent will be those that have occurred (or will occur) since the last Snapshot, Subscription, or Change Log access.
- Change Log. All add, delete, and update transactions that have been generated since the last Snapshot, Subscription, or Change Log access will be transmitted.
- SSO Event. Identity information about the current user is transmitted at the start of a session. This is the existing Shibboleth access type.
Detailed design:
Data Release and Governance
...
The first principle in this document is "Campus identity and access management systems and the organizations that operate them are authoritative for information about the members of their respective communities. The same campus organization that currently operates Shibboleth will be the organization that operates the infrastructure described in this document." (See Principles and Assumptions above.) In many cases, however, the organizations that operate the campus identity and access management (IAM) systems are not the ultimate proprietors of the data in their systems, so the IAM operators must represent the data release policies of those proprietors.
We also have the following principles:
- As the focus on UC-wide service provisioning grows, there will be a corresponding expansion in the number of attributes which need to be released within the UCTrust federation. This will require stronger partnerships and governance agreements between IDMS organizations and data proprietors on each campus.
- The existing UCTrust agreements, policies, processes, and technology should be leveraged as much as possible. All participating campuses have implemented UCTrust and are operating a current version of Shibboleth.
It is already the case that IAM operators aggreate data for UCTrust, but this User Provisioning project represents a significant expansion of that role. It also represents an expansion of the UCTrust Work Group's role of defining interoperable names and formats for identity attributes.
IAM operators need to ensure that the appropriate organizational relationships are in place to enable the IAM operator to aggregate data from multiple source systems, such as payroll and student information systems, so that decisions about the release of identity attributes to service providers can be made in an effective manner.
Roles and Responsibilities
...
- Lots of momentum in industry
- Still immature
- Elegant in it's simplicity
- Wouldn't be able to deliver range if data needed without significant further development
- We could influence the course and pace if of it's maturation
SPML
- Not much uptake/active development in industry, with the exception of Oracle which relies heavily on SPML
...
UCOP-Trappist-Magic-Quadrant-2.pdf
Chosen Protocol
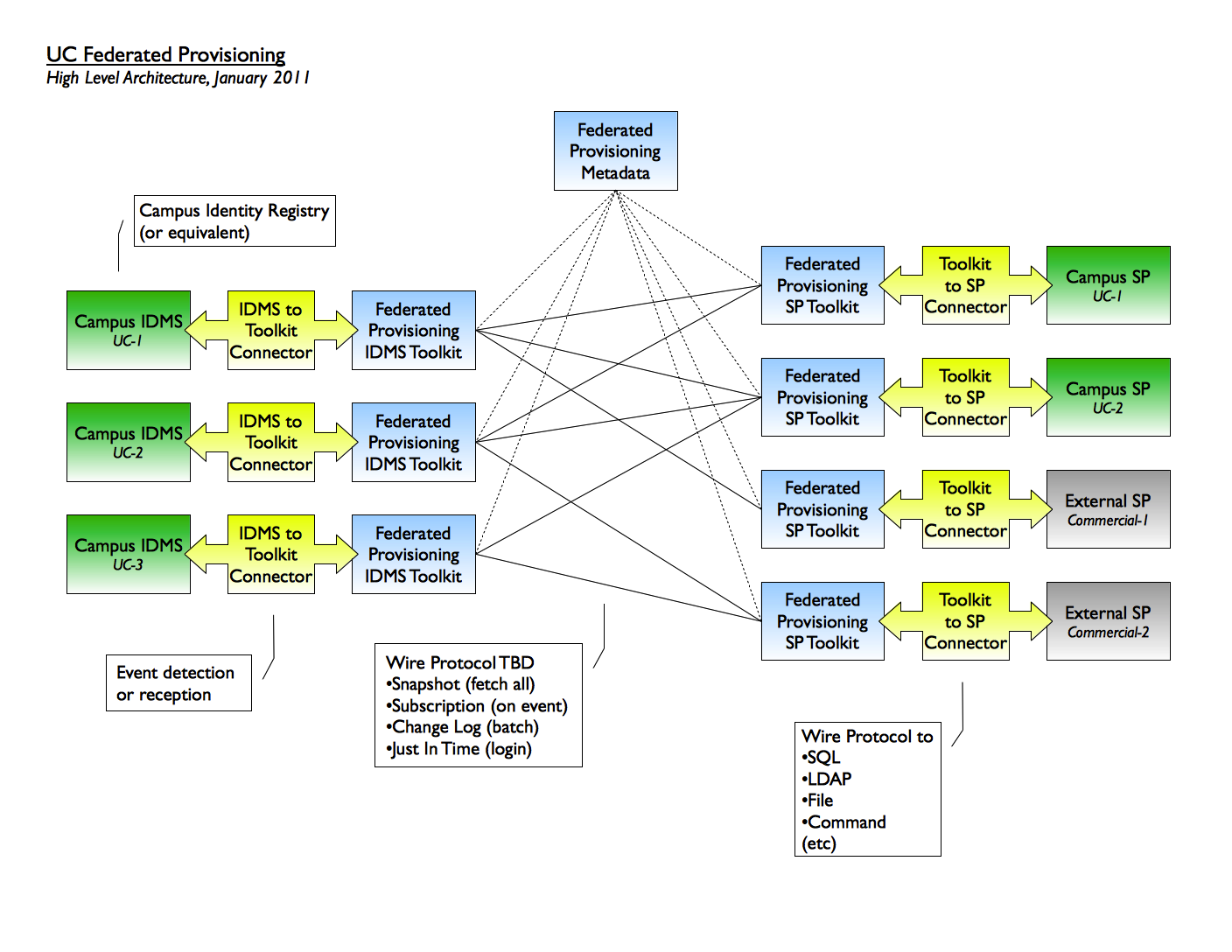
For this project, the group has chosen SAML for the wire (the "mesh" in the Detailed Design diagram) protocol. This means that the IDMSTK and the SPTK will use SAML for communication. SAML was chosen because it is already used by Shibboleth, and with the advent of the Change Notify protocol, it was seen as the best option in terms of meshing with current infrastructure/processes.
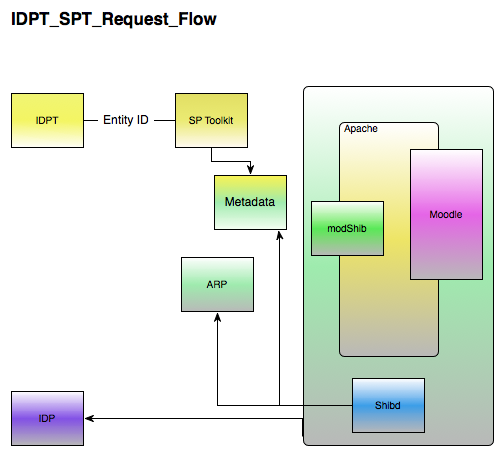
Sample Request Flow
IdP toolkit
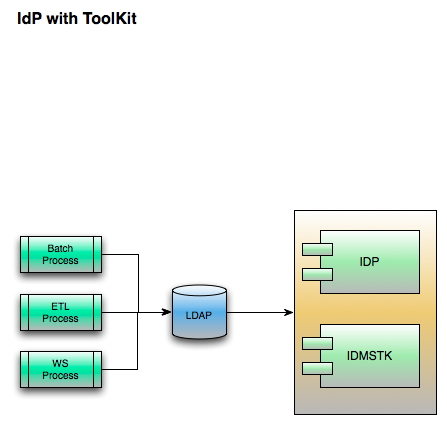
IDMS Toolkit
The IDMS Toolkit (IDMSTK) is a program which accepts requests from the various SPTKs (see SPTK section, below) for the purposes of account provisioning in a service provider. There is only one IDMSTK per institution, where there could be n SPTKs. The IDMSTK processes basic requests sent from the various SPTKs, and in turn, looks into the institution's local IDMS to fulfill the request. It is possible that not every institution's IDMS will be able to respond to all of the requests.
The IDMSTK will be able to answer the following types of requests:
- Get all of the changed IDs since the given time:
getChangedSubjects(Time t) - Get all changes for the given subject since the given time:
getChangesForSubjectSinceTime(SubjectID id, Time t) - Get current state of the given subject:
getSubject(SubjectID id) - Get the current state of everyone:
getAll()
| Info | ||
|---|---|---|
| ||
The second bullet above is not 100% clear to me, as I don't think we can expect an IDMS to be able to relay all changes for a given person from a given point in time. So, if someone can clarify this one, that will be great. - Lucas Rockwell |
The requests outlined above will be performed over the wire using SAML (see reason for this in the Wire Protocols section, above).
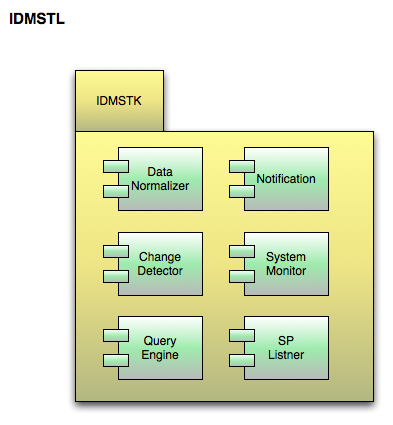
The IDMSTK is comprised of the following:
- Query Engine
- ARP
- Notifications
- Config
- Change Detector
- System Monitor
- ListenerSee diagrams below
*
SP Toolkit
...
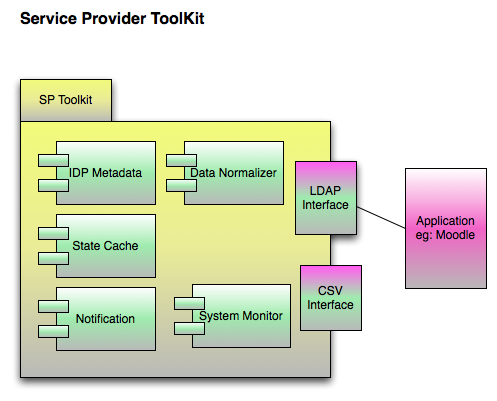
The SP Toolkit (SPTK) is a tool which will allow a local service, Moodle in the example above, to pull in data from multiple sources as if it were only talking to one source. For instance, Moodle can be configured to pull provisioning information from a single LDAP instance, so in this case, the SPTK will allow Moodle to be configured so that it pulls provisioning data from LDAP, but that LDAP is actually the SPTK, and the SPTK in turn pulls in provisioning information from each UC's IdPTK.
See the IDMSTK section above for a list of the types of request that the SPTK should be able to handle from the service provider.
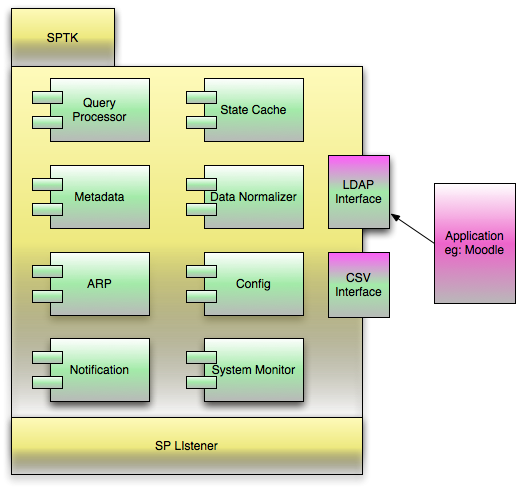
The SPTK is comprised of the following:
- SP Interface – The interface used by the service which will use (read, query) the SPTK. In the case of Moodle, the Interface will be LDAP. As mentioned above, the SPTK can only handle basic query processing, so this is not a full-featured LDAP interface.
- Query Processor – Will take the native query from the service and translate it into a SAML request that the IDMSTK will be able to understand.
- Metadata – Metadata for the various institutions in the trust relationship for this SPTK. This allows the SPTK to know where the IDMSTKs are located.
- ARP --
- Notifications
- State Cache
- Data Normalizer
- Config
- System Monitor
- Listener
Related Links
...